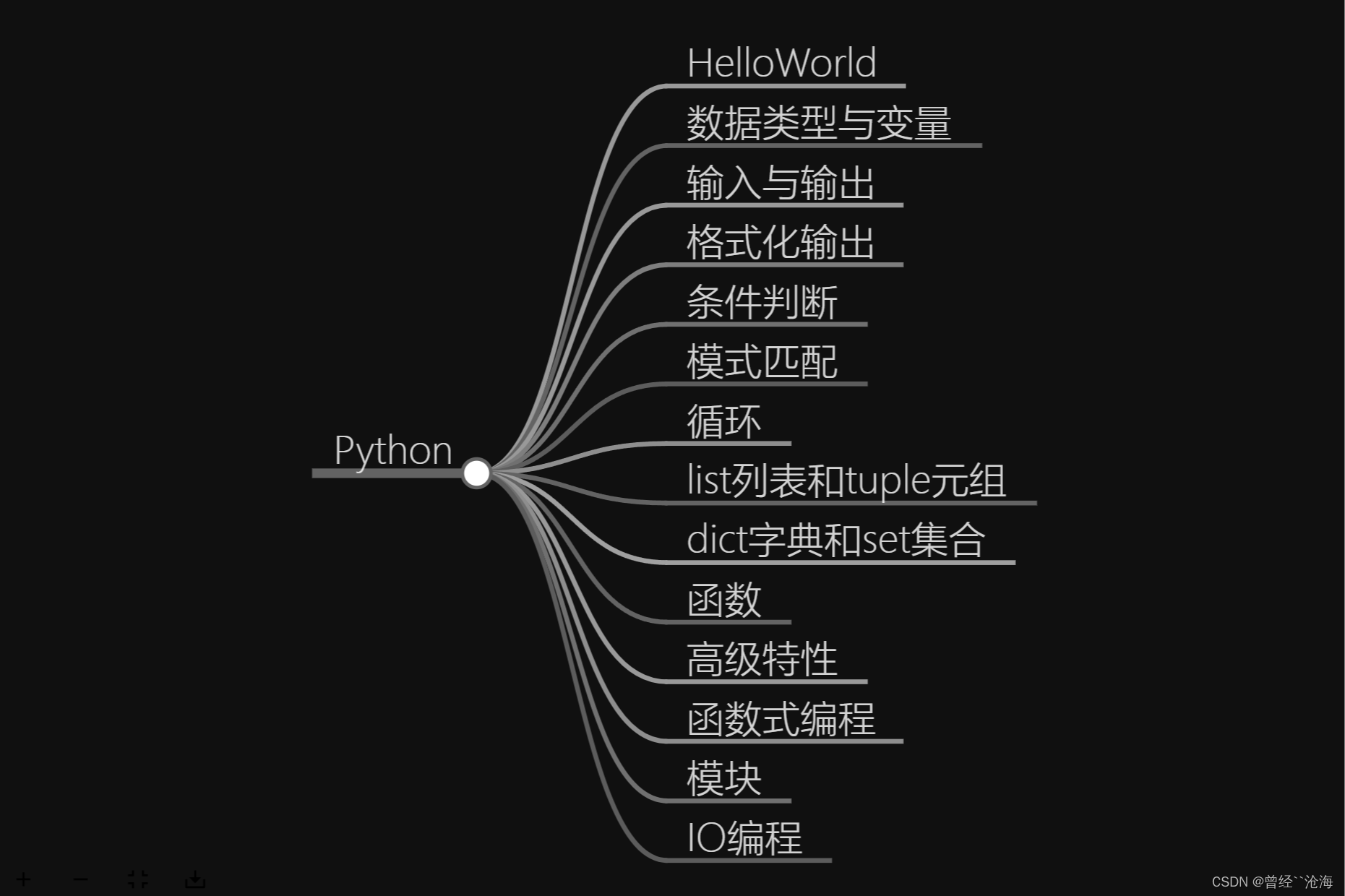
Python
首先 python 并不是简单,什么语言都有基础和高级之分,要想掌握一门语言,必须把高级部分掌握才行。
HelloWorld
helloWorld.py
print('hello, world')
数据类型与变量
| 变量的数据类型 | 数据类型描述 | 变量的定义方式 |
|---|---|---|
| 整数型 (int) | 整数,没有小数部分 | age = 25 |
| 浮点型 (float) | 浮点数,有小数部分或采用科学计数法 | temperature = 36.6 |
| 字符串 (str) | 字符串,由字符组成的序列 | name = "Alice" |
| 布尔型 (bool) | 列表,有序且可以包含不同类型的元素 | is_student = True |
| 列表 (list) | 元组,不可变的有序元素序列 | fruits = ["apple", "banana", "cherry"] |
| 元组 (tuple) | 字典,无序的键值对集合 | coordinates = (10.0, 20.0) |
| 字典 (dict) | 集合,无序的不重复元素集合 | person = {"name": "John", "age": 30} |
| 集合 (set) | 布尔值,表示真(True)或假(False) | colors = {"red", "green", "blue"} |
| 空值 (NoneType) | 表示空值,其唯一值是None | nothing = None |
dataType.py
# 整数型 (int) 整数,没有小数部分
age = 25
# 浮点型 (float) 浮点数,有小数部分或采用科学计数法
temperature = 36.6
# 字符串 (str) 字符串,由字符组成的序列
name = "Alice"
# 布尔型 (bool) 列表,有序且可以包含不同类型的元素
is_student = True
# 列表 (list) 元组,不可变的有序元素序列
fruits = ["apple", "banana", "cherry"]
# 元组 (tuple) 字典,无序的键值对集合
coordinates = (10.0, 20.0)
# 字典 (dict) 集合,无序的不重复元素集合
person = {"name": "John", "age": 30}
# 集合 (set) 布尔值,表示真(True)或假(False)
colors = {"red", "green", "blue"}
# 空值 (NoneType) 表示空值,其唯一值是None
nothing = None
输入与输出
printAndInput.py
name = input() # input获取的输入永远返回字符串str
print(' hello,', name)
name = input('please enter your name: ')
print(' hello,', name)
格式化输出
formatPrint.py
两种方式
ptint('... %_ ... %_ ...' % (var1,var2...))
print(f'... {var1} ... {var2} ...')
占位符
| 占位符 | 替换内容 |
|---|---|
| %d | 整数(可指定位数’%03d’) |
| %f | 浮点数(可指定位数’%.9f’) |
| %s | 字符串 |
| %x | 十六进制整数 |
条件判断
ifElse.py
birth = input('birth: ') # input获取的输入永远返回字符串str
birth = int() # 强制类型转化 str->int
age = 2024 - birth
print('your age is %03d'% age) # 格式化使输出
if birth < 2000 and birth >= 1900: # 条件判断
print('90后')
elif birth >= 2000:
print('00后')
else:
print('90前')
模式匹配
模式匹配:变量
age = 15
match age:
case x if x < 10:
print(f'{x} < 10 years old: {x}')
case 10:
print('10 years old.')
case 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18:
print('11~18 years old.')
case 19:
print('19 years old.')
case _:
print('not sure.')
# 在上面这个示例中,第一个case x if x < 10表示当age < 10成立时匹配,且赋值给变量x,第二个case 10仅匹配单个值,第三个case 11|12|...|18能匹配多个值,用|分隔。最后一个case _表示其他所有情况。
模式匹配:列表
args = ['gcc', 'hello.c', 'world.c']
# args = ['clean']
# args = ['gcc']
match args:
# 如果仅出现gcc,报错:
case ['gcc']:
print('gcc: missing source file(s).')
# 出现gcc,且至少指定了一个文件:
case ['gcc', file1, *files]:
print('gcc compile: ' + file1 + ', ' + ', '.join(files))
# 仅出现clean:
case ['clean']:
print('clean')
case _:
print('invalid command.')
# 第一个case ['gcc']表示列表仅有'gcc'一个字符串,没有指定文件名
# 第二个case ['gcc', file1, *files]表示列表第一个字符串是'gcc',第二个字符串绑定到变量file1,后面的任意个字符串绑定到*files,它表示至少指定一个文件;
# 第三个case ['clean']表示列表仅有'clean'一个字符串;
循环
for…in循环,依次把list或tuple中的每个元素迭代出来
# range()函数,可以生成一个整数序列,再通过list()函数可以转换为list
## exp1
numbers = list(range(101))
sum = 0
for x in numbers:
sum = sum + x
print(sum)
# exp2
L = ['Bart', 'Lisa', 'Adam']
for x in L:
if x == 'Adam':
break
if x == 'Bart':
continue
print('Hello,%s!' %x)
while循环,只要条件满足,就不断循环,条件不满足时退出循环。
sum = 0
n = 100
while n > 0:
sum = sum + n
n = n - 1
print(sum)
list列表和tuple元组
列表
list是一种有序的集合,可以随时添加和删除其中的元素。
classmates = ['Michael', 'Bob', 'Tracy']
# len()函数可以获得list元素的个数:
len(classmates)
# 索引来访问list中每一个位置的元素:
classmates[0]
# 最后一个元素的索引是:
len(classmates) - 1
# 最后一个元素:
classmates[-1]
# 追加元素:
classmates.append('Adam')
# 入到指定的位置:
classmates.insert(1, 'Jack')
# 删除list末尾的元素:
classmates.pop()
# 删除指定位置的元素:
classmates.pop(i)
# 把某个元素替换成别的元素,复制索引:
classmates[1] = 'Sarah'
# list里面的元素的数据类型也可以不同:
L = ['Apple', 123, True]
# list元素也可以是另一个list:
s = ['python', 'java', ['asp', 'php'], 'scheme'];要拿到'php'可以写p[1]或者s[2][1]
# 排序:
a.sort()
元组
tuple和list非常类似,但是tuple一旦初始化就不能修改,不可变性使得代码更安全
classmates = ('Michael', 'Bob', 'Tracy')
# 现在,classmates这个tuple不能变了,它也没有append(),insert()这样的方法。
#其他获取元素的方法和list是一样的,但不能赋值成另外的元素
classmates[0]
classmates[-1]
#只有1个元素的tuple定义时必须加一个逗号‘,’,来消除歧义:
t = (1,)
#“可变的”tuple:
t = ('a', 'b', ['A', 'B'])
t[2][0] = 'X'
t[2][1] = 'Y'
#表面上看,tuple一开始指向的list并没有改成别的list,准确说tuple并没有变
dict字典和set集合
dict字典
dict字典在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度
# 初始化放数据
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
print(d['Michael'])
# 通过key放数据
d['Adam'] = 67
print(d['Adam'])
# 通过key修改value
d['Adam'] = 88
print(d['Adam'])
# 避免因key不存在而报错,如果key不存在,返回None,或者指定的value
d.get('Thomas')#返回None
d.get('Thomas', -1)#返回-1
# 删除key
d.pop('Bob')
d
# 牢记dict的key必须是不可变对象。作为key的对象不能变。在Python中,字符串、整数等都是不可变的,因此,可以放心地作为key。而list是可变的,就不能作为key:
set集合
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,set自动去重。
# 创建一个set,需提供一个list作为输入集合
s = set([1, 2, 3])
# 添加元素
s.add(4)
# 删除元素
s.remove(4)
# 两个set可以做数学意义上的交集、并集等操作
s1 = set([1, 2, 3])
s2 = set([2, 3, 4])
(s1 & s2)
(s1 | s2)
# set和dict的唯一区别仅在于没有存储对应的value,但是,set的原理和dict一样,所以,同样不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证set内部“不会有重复元素”。
函数
调用函数
内置函数
# 可以把函数名赋给一个变量,相当于给这个函数起了一个“别名”:
a = abs # 变量a指向abs函数
a(-1) # 所以也可以通过a调用abs函数
定义函数
# 空函数,可以用pass语句
def nop():
pass
# 参数检查
def my_abs(x):
if not isinstance(x, (int, float)):
raise TypeError('bad operand type')
else:
...
# 返回多值,这只是一种假象,Python函数返回的仍然是单一值,返回一个tuple,在语法上返回一个tuple可以省略括号
def move(x, y, step, angle=0):
...
return nx, ny
函数的参数
1. 默认参数
使用默认参数时注意:
- 必选参数在前,默认参数在后。
- 设置默认参数时,把变化大的参数放前面,变化小的参数放后面。变化小的参数就可以作为默认参数。
- 默认参数一定要用不可变对象,如果是可变对象,程序运行时会有逻辑错误!
# 由于我们经常计算x2,所以,完全可以把第二个参数n的默认值设定为2
def power(x, n=2):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
# 定义默认参数要牢记一点:默认参数必须指向不变对象!
def add_end(L=None):
if L is None:
L = []
L.append('END')
return L
2. 可变参数 *
定义语法:args是可变参数,args接收的是一个tuple
传参语法:可变参数既可以直接传入:func(1, 2, 3),又可以先组装list或tuple,再通过args传入:func(*(1, 2, 3));
# 传入的参数个数是可变的,可以是0个、1个到任意个。
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
# 调用
calc(1, 2, 3, 4, 5)
# 如果已经有一个list或者tuple,要调用一个可变参数,可以把list或tuple的元素变成可变参数传进去
calc(*nums) # *nums表示把nums这个list的所有元素作为可变参数传进去。
3. 关键字参数 **
定义语法:**kw是关键字参数,kw接收的是一个dict
传参语法:关键字参数既可以直接传入:func(a=1, b=2),又可以先组装dict,再通过**kw传入:func(**{‘a’: 1, ‘b’: 2})。
# 关键字参数在函数内部自动组装为一个dict,个数不受限
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)
# 调用
person('Michael', 30) # 结果 name: Michael age: 30 other: {};
person('Adam', 45, gender='M', job='Engineer')# 结果 name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'}
4. 命名关键字参数 分隔符 ,*,
命名的关键字参数是为了限制调用者可以传入的参数名,同时可以提供默认值。
定义命名的关键字参数在没有可变参数的情况下不要忘了写分隔符*,否则定义的将是位置参数。
# 命名关键字参数必须传入参数名
def person(name, age, *, city, job):
print(name, age, city, job)
# 调用
person('Jack', 24, city='Beijing', job='Engineer')
递归函数
如果一个函数在内部调用自身本身,这个函数就是递归函数。
def fact(n):
if n==1:
return 1
return n * fact(n - 1)
高级特性
切片、迭代、列表生成式、生成器、迭代器
切片索引
def trim(s):
start, end = 0, len(s)
# 找到第一个非空格字符的索引
while start < end and s[start].isspace():
start += 1
# 找到最后一个非空格字符的索引
while end > start and s[end - 1].isspace():
end -= 1
# 返回去除首尾空格后的字符串
return s[start:end]
# 示例用法
original_string = " Hello, World! "
trimmed_string = trim(original_string)
print(trimmed_string)
迭代
如果给定一个list或tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称为迭代(Iteration),对于python只要是可迭代对象,无论有无下标,都可以迭代,比如dict就可以迭代
d = {'a': 1, 'b': 2, 'c': 3}
for key in d:
for value in d.values():
for ch in 'ABC':
# Python内置的enumerate函数可以把一个list变成索引-元素对,这样就可以在for循环中同时迭代索引和元素本身:
for i, value in enumerate(['A', 'B', 'C']):
# 两个变量
for x, y in [(1, 1), (2, 4), (3, 9)]:
列表生成式
# 要生成[1x1, 2x2, 3x3, ..., 10x10]列表并仅筛选出偶数的平方
[x * x for x in range(1, 11) if x % 2 == 0] # 此处if是过滤条件
# for循环其实可以同时使用两个甚至多个变量,比如dict的items()可以同时迭代key和value:
d = {'x': 'A', 'y': 'B', 'z': 'C' }
for k, v in d.items():
print(k, '=', v)
# 列表生成式也可以使用两个变量来生成list:
[k + '=' + v for k, v in d.items()]
# 把一个list中所有的字符串变成小写:
L = ['Hello', 'World', 'IBM', 'Apple']
[s.lower() for s in L]
# if...else表达式
[x if x % 2 == 0 else -x for x in range(1, 11)]
# isinstance函数用于检查一个对象是否属于指定的类型或类型元组
# 检查整数类型
x = 5
result = isinstance(x, int)
# 检查字符串类型
y = "Hello"
result = isinstance(y, str)
# 检查多个类型
z = 3.14
result = isinstance(z, (int, float))
print(result) # 输出 True,因为 z 是 int 或 float 类型之一
生成器generator
在Python中,这种一边循环一边计算的机制,称为生成器:generator。
# 1.列表生成式的[]改成(),就创建了一个generator
L = [x * x for x in range(10)] #列表生成器
g = (x * x for x in range(10)) #生成器
# 打印
next(g)
for n in g:
print(n)
# 2.generator函数
def odd():
print('step 1')
yield 1
print('step 2')
yield(3)
print('step 3')
yield(5)
o = odd()
next(o)
next(o)
next(o)
迭代器Iterator
Iterable对象,诸如list、tuple、dict、set、str、generator,凡是可作用于for循环的对象都是Iterable类型
Iterator对象:凡是可作用于next()函数的对象都是Iterator类型
生成器都是Iterator对象,其他如list、dist、str等可以使用iter()函数由Iterable变成Iterator
isinstance('abc',Iterable) # True
isinstance('abc',Iterator) # False
isinstance(iter('abc'), Iterator) # True
函数式编程
高阶函数
高阶函数(Higher-Order Function)是指能够接受其他函数作为参数或者将函数作为结果返回的函数。在函数式编程中,高阶函数是一种重要的概念,它能够提高代码的灵活性和表达力。
# 变量可以指向函数
# 函数名也是变量
# 传入函数
def add(x, y, f):
return f(x) + f(y)
map/reduce
map()函数接收两个参数,一个是函数,一个是Iterabl对象,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
def f(x):
return x * x
r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9]) # 函数f作用域Iterable对象的每个元素,结果r是一个Iterator
list(r) #Iterator是惰性序列,通过list()函数让它把整个序列都计算出来并返回一个list
list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
reduce()把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算。
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
# 比如序列求和
def add(x, y):
return x + y
reduce(add, [1, 3, 5, 7, 9])
# 当然求和运算可以直接用Python内建函数sum(),没必要动用reduce。
#但是如果要把序列[1, 3, 5, 7, 9]变换成整数13579,reduce就可以派上用场
def fn(x, y):
return x * 10 + y
reduce(fn, [1, 3, 5, 7, 9])
# 配合map(),我们就可以写出把str转换为int的函数
def fn(x, y):
return x * 10 + y
def char2num(s):
digits = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
return digits[s]
reduce(fn, map(char2num, '13579'))
# lambda 是 Python 中的一个关键字,用于创建小型的匿名函数。
numbers = [1, 2, 3, 4, 5]
squared = list(map(lambda x: x**2, numbers))
print(squared) # 输出 [1, 4, 9, 16, 25]
filter
Python内建的filter()函数用于过滤序列。和map()类似,filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
# 例如,在一个list中,删掉偶数,只保留奇数
def is_odd(n):
return n % 2 == 1
list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]))
# 结果: [1, 5, 9, 15]
sorted
#Python内置的sorted()函数就可以对list等更高你抽象进行排序
sorted([36, 5, -12, 9, -21])
#sorted()函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序
sorted([36, 5, -12, 9, -21], key=abs)
sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower)
#要进行反向排序,不必改动key函数,可以传入第三个参数reverse=True
sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True)
返回函数
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum
f = lazy_sum(1, 3, 5, 7, 9)
f
f()
#当lazy_sum返回函数sum时,相关参数和变量都保存在返回的函数中,这种称为“闭包(Closure)”
匿名函数
# lambda x: x * x 实际上就是:
def f(x):
return x * x
f = lambda x: x * x
f
装饰器
假设我们要增强now()函数的功能,比如,在函数调用前后自动打印日志,但又不希望修改now()函数的定义,这种在代码运行期间动态增加功能的方式,称之为“装饰器”(Decorator)。
函数对象有一个__name__属性,可以拿到函数的名字
借助Python的@语法,把decorator置于函数的定义处
#首先定义一个能打印日志的decorator
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
@log # 把@log放到now()函数的定义处,相当于执行了语句now = log(now)
def now():
print('2024-4-29')
#如果decorator本身需要传入参数,那就需要编写一个返回decorator的高阶函数
def log(text):
def decorator(func):
def wrapper(*args, **kw):
print('%s %s():' % (text, func.__name__))
return func(*args, **kw)
return wrapper
return decorator
@log('execute') #相当于执行语句now = log('execute')(now)
def now():
print('2024-4-29')
#经过decorator装饰之后的函数,它们的__name__已经从原来的'now'变成了'wrapper',这样会导致有些依赖函数签名的代码执行出错。
#python内置的functools.wraps可以解决
import functools
def log(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
偏函数
int()函数可以把字符串转换为整数,当仅传入字符串时,int()函数默认按十进制转换,传入base参数,就可以做N进制的转换:
int('12345', base=8)
int('12345', base=16)
#functools.partial就是帮助我们创建一个偏函数的,不需要我们自己定义int2()
int2 = functools.partial(int, base=2)
int2('1000000') # 就是字符串转二进制了
# 总结functools.partial的作用就是,把一个函数的某些参数默认值改一下,返回一个新的函数,调用这个新函数会更简单。
模块
使用模块
Python本身就内置了很多非常有用的模块,只要安装完毕,这些模块就可以立刻使用。
# 使用sys模块的第一步,就是导入该模块:
import sys
# 导入sys模块后,我们就有了变量sys指向该模块,利用sys这个变量,就可以访问sys模块的所有功能
def test():
args = sys.argv
# if __name__=='__main__':这个条件语句判断一个 Python 脚本是否作为主程序执行。如果该脚本被直接执行,而不是被导入,则执行一些特定的操作
def my_function():
print("This is a function in the module.")
if __name__ == '__main__':
print("This is the main part of the script.")
my_function()
安装第三方模块
在Python中,安装第三方模块,是通过包管理工具pip完成的。
pip install Pillow
IO编程
文件读写
读文件
# 要以读文件的模式打开一个文件对象,使用Python内置的open()函数,传入文件名和标示符
f = open('/Users/michael/test.txt', 'r')
# 如果文件打开成功,接下来,调用read()方法可以一次读取文件的全部内容,Python把内容读到内存,用一个str对象表示
f.read()
# 最后一步是调用close()方法关闭文件,从而释放操作系统的资源
f.close()
# 敲黑板:Python引入了with语句来自动帮我们调用close()方法,这样就不要担心忘记f.close()了
with open('/path/to/file', 'r') as f:
print(f.read())
#二进制文件,比如图片、视频等等,用'rb'模式打开文件即可
f = open('/Users/michael/test.jpg', 'rb')
f.read()
# 字符编码,要读取非UTF-8编码的文本文件,需要给open()函数传入encoding参数
f = open('/Users/michael/gbk.txt', 'r', encoding='gbk')
f.read()
# open()函数还接收一个errors参数,表示如果遇到编码错误后如何处理。
f = open('/Users/michael/gbk.txt', 'r', encoding='gbk',errors='ignore')
f.read()
写文件
# 和读文件唯一区别是调用open()函数时,传入标识符'w'或者'wb'表示写文本文件或写二进制文件
f = open('/Users/michael/test.txt', 'w')
f.write('Hello, world!')
f.close()
# 不要忘了close(),要避免就使用with open表达式
with open('/Users/michael/test.txt', 'w') as f:
f.write('Hello, world!')
StringIO和BytesIO
StringIO和BytesIO是在内存中操作str和bytes的方法,使得和读写文件具有一致的接口。
StringIO
StringIO顾名思义就是在内存中读写str。
# 要把str写入StringIO,我们需要先创建一个StringIO,然后,像文件一样写入即可
from io import StringIO
f = StringIO()
f.write('hello')
f.write(' ')
f.write('world!')
print(f.getvalue()) # hello world!
# 可以用一个str初始化StringIO,然后,像读文件一样读取
f = StringIO('Hello!\nHi!\nGoodbye!')
while True:
s = f.readline()
if s == '':
break
print(s.strip())
BytesIO
如果要操作二进制数据,就需要使用BytesIO
from io import BytesIO
f = BytesIO()
f.write('中文'.encode('utf-8'))
print(f.getvalue())
#注意,写入的不是str,而是经过UTF-8编码的bytes
操作文件和目录
如果我们要操作文件、目录,可以在命令行下面输入操作系统提供的各种命令来完成。比如dir、cp等命令。